Transductive Multi-label Zero-shot Learning
Yanwei Fu, Yongxing Yang, Timothy M. Hospedales, Tao Xiang and Shaogang Gong
School of EECS, Queen Mary University of London, UK
{y.fu,yongxin.yang,t.hospedales, t.xiang, s.gong}@qmul.ac.uk
Abstract
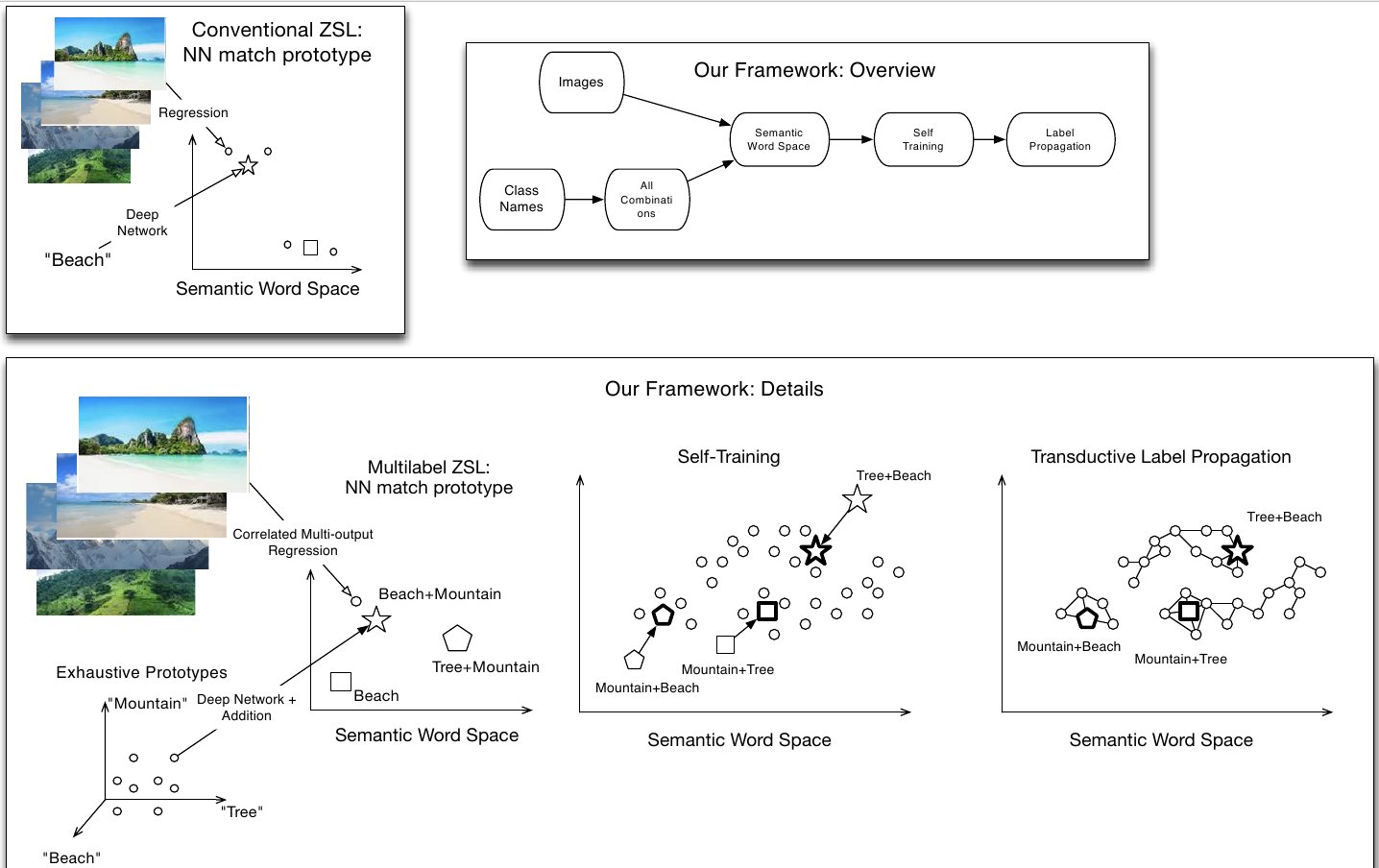
Zero-shot learning has received increasing interest as a means to alleviate the often prohibitive expense of annotating training data for large scale recognition problems. These methods have achieved great success via learning intermediate semantic representations in the form of attributes and more recently, semantic word vectors. However, they have thus far been constrained to the single-label case, in contrast to the growing popularity and importance of more realistic multi-label data. In this paper, for the first time, we investigate and formalise a general framework for multi-label zero-shot learning, addressing the unique challenge therein: how to exploit multi-label correlation at test time with no training data for those classes? In particular, we propose (1) a multi-output deep regression model to project an image into a semantic word space, which explicitly exploits the correlations in the intermediate semantic layer of word vectors; (2) a novel zero-shot learning algorithm for multi-label data that exploits the unique composition- ality property of semantic word vector representations; and (3) a transductive learning strategy to enable the regression model learned from seen classes to generalise well to unseen classes. Our zero-shot learning experiments on a number of standard multi-label datasets demonstrate that our method outperforms a variety of baselines.1-page abstract
Download
Download-readme
data for several dataset used in our papers
We are using all wikipedia articles to train the google word2vec recurrent neural network model
and generate the semantic word vector dictionary; and we will release it to the community.
Paper:
[1] Fu, Yanwei; Yang, Yongxin, Hospedales, T.; Xiang, T.; Gong, S: Transductive Multi-label Zero-Shot learning, (BMVC 2014). Paperbib: @INPROCEEDINGS{embedding2014ECCV,
author = { Yanwei Fu and Yongxing Yang and Timothy M. Hospedales and Tao Xiang and Shaogang Gong},
title = {Transductive Multi-label Zero-Shot Learning},
booktitle ={BMVC},
year = {2014}
}
[2] Fu, Yanwei; Hospedales, T.; Xiang, T.; Fu, Z.; Gong, S: Transductive Multi-view Embedding for Zero-Shot Recognition and Annotation, (ECCV 2014). Paper
bib: @INPROCEEDINGS{embedding2014ECCV,
author = { Yanwei Fu and Timothy M. Hospedales and Tao Xiang and Zhenyong Fu and Shaogang Gong},
title = {Transductive Multi-view Embedding for Zero-Shot Recognition and Annotation},
booktitle = {ECCV},
year = {2014}
}
bib: @INPROCEEDINGS{embedding2014ECCV,
author = { Yanwei Fu and Timothy M. Hospedales and Tao Xiang and Shaogang Gong},
title = {Transductive multi-view zero-shot recognition and annotation},
booktitle = {submitted to TPAMI},
year = {2014}
}