Attribute Learning for Understanding Unstructured Social Activity
Yanwei Fu, Timothy M. Hospedales, Tao Xiang, and Shaogang
Gong
School of EECS, Queen Mary University of London, UK
{yanwei.fu,tmh,txiang,sgg}@eecs.qmul.ac.uk
 snap
of dataset
snap
of dataset
Download
Download
Including raw images, features, and train/test partitions.
Visualizing detected user-defined and data-driven attributes (localization to the frame-level for each attribute/event)
Download
More examples shown from Fig 10.
Details
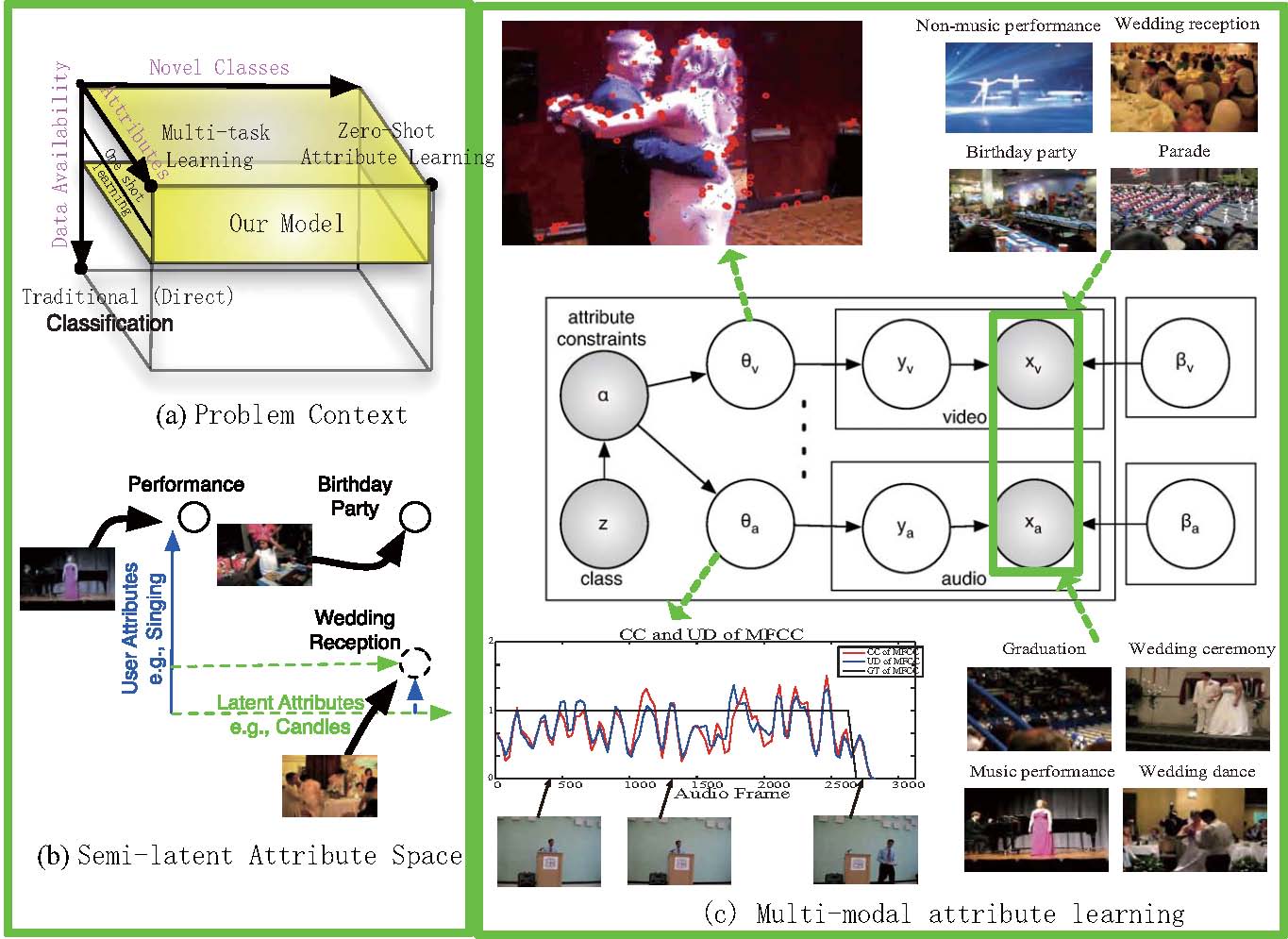
The USAA dataset includes 8 different semantic class videos which are home videos of social occassions such e birthday party, graduation party,music performance, non-music performance, parade, wedding ceremony, wedding dance and wedding reception which feature activities of group of people. It contains around 100 videos for training and testing respectively. Each video is labeled by 69 attributes. The 69 attributes can be broken down into five broad classes: actions, objects, scenes, sounds, and camera movement. It can be used for evaluating approaches for video classification, N-shot and zero-shot learning, multi-task learning, attribute/concept-annotation, attribute/concepts-modality prediction, suprising attributes/concepts discovery, and latent-attribute(concepts) discovery etc.
The ontology attribute definitions of these 8 classes are from their wikipedia definitions; and can be downloaded from here.
The dataset mat files includes the following
strucutures:
Xtrain: the low level features of training
video data
Xtest: the low level features of testing video data. Also note that there are several videos of all 0 low-level
features (<5) due to some problems of extracting
process. The low-level features are soft-weighted[1].
train_attr: the user-defined 69 binary video
attributes of training videos
test_attr: the user-defined 69 binary video
attributes for testing videos.
train_video_label: the training video class
labels for the 8 classes
test_video_label: the testing video class
labels for the 8 classes
train_video_name: the index of training
videos
test_video_name: the index of testing videos
train_video_name and test_video_name
are the index of the following two Youtube
IDs files. These two files contains unique YouTube
IDs of 4659 training videos and YouTube IDs of 4658 test
videos. And the index are the line number corresponding
to these two files. These Youtube IDs comes from CCV
dataset. (We hope to release the original video
data, but it seems that there will be some authourity
problems from Youtube. So, we can only provide the
Youtube IDs. However, you can easily download the videos
by using the python
downloader.My download method is to generate a Linux
batch program(.sh) and each line invokes the python
downloader file downloading one video. )
If you use this dataset, please cite papers below note
-
Attribute Learning for Understanding Unstructured
Social Activity
Y. Fu, T. Hospedales, T. Xiang and S. Gong
ECCV 2012
PDF - Learning Multi-modal Latent Attributes
Y. Fu, T. Hospedales, T. Xiang and S. Gong
IEEE TPAMI (to appear)
Xplore PDF
To repeat the Zero-shot learning results of USAA in our PAMI paper, we are using the following settings: We use three splits for ZSL, and the zero-shot (testing classes) are [1,2,4,7];[1,6,7,8],[2,4,5,6]; Since we provide instance-level for each video, the binary class-level prototype should be mean(attribute(video==classname,:))>Threshold; i.e. the mean of the video attributes belong to the same class; And the threshold=0.5.
More related work:
[2] Yu-Gang Jiang, Guangnan Ye, Shih-Fu Chang, Daniel Ellis, Alexander C. Loui, Consumer Video Understanding: A Benchmark Database and An Evaluation of Human and Machine Performance, ACM International Conference on Multimedia Retrieval (ICMR), Trento, Italy, Apr. 2011.